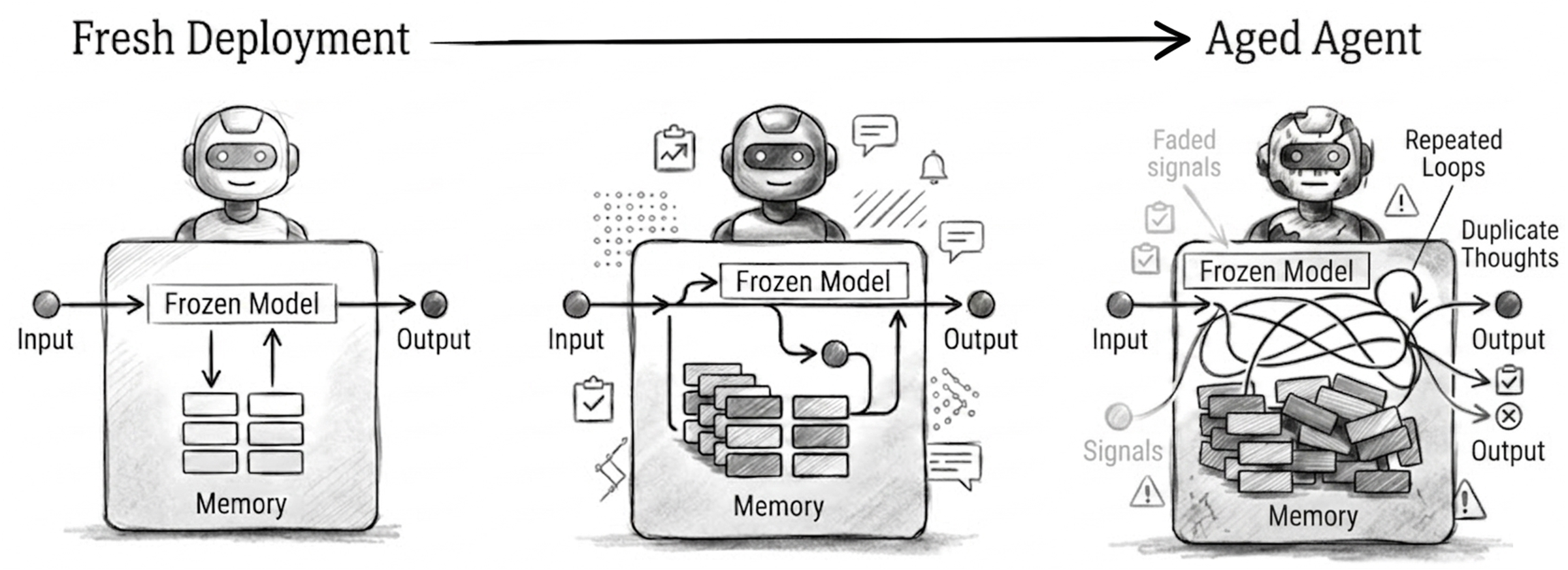
Long-lived AI agents are increasingly deployed as persistent operational systems, yet they are still evaluated like freshly initialized models. Day-one benchmarks miss a basic systems question: how long does an agent remain reliable after deployment? Even when model weights are frozen, an agent's effective state keeps changing as it compresses interaction history, retrieves from a growing memory store, revises facts after updates, and undergoes routine maintenance. Reliability therefore becomes a lifespan property of the full agent harness, not only a snapshot property of the base model.
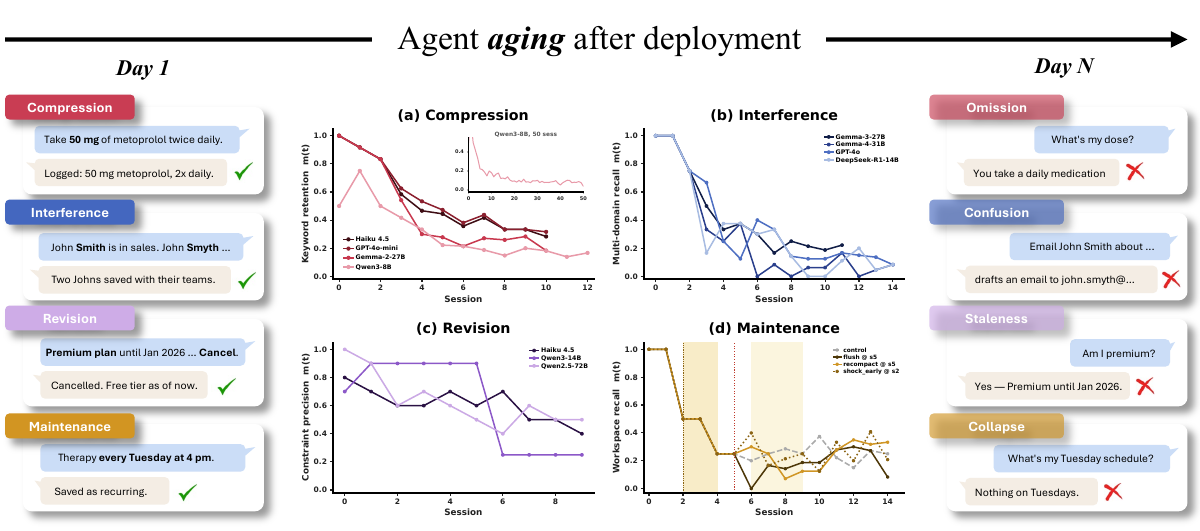
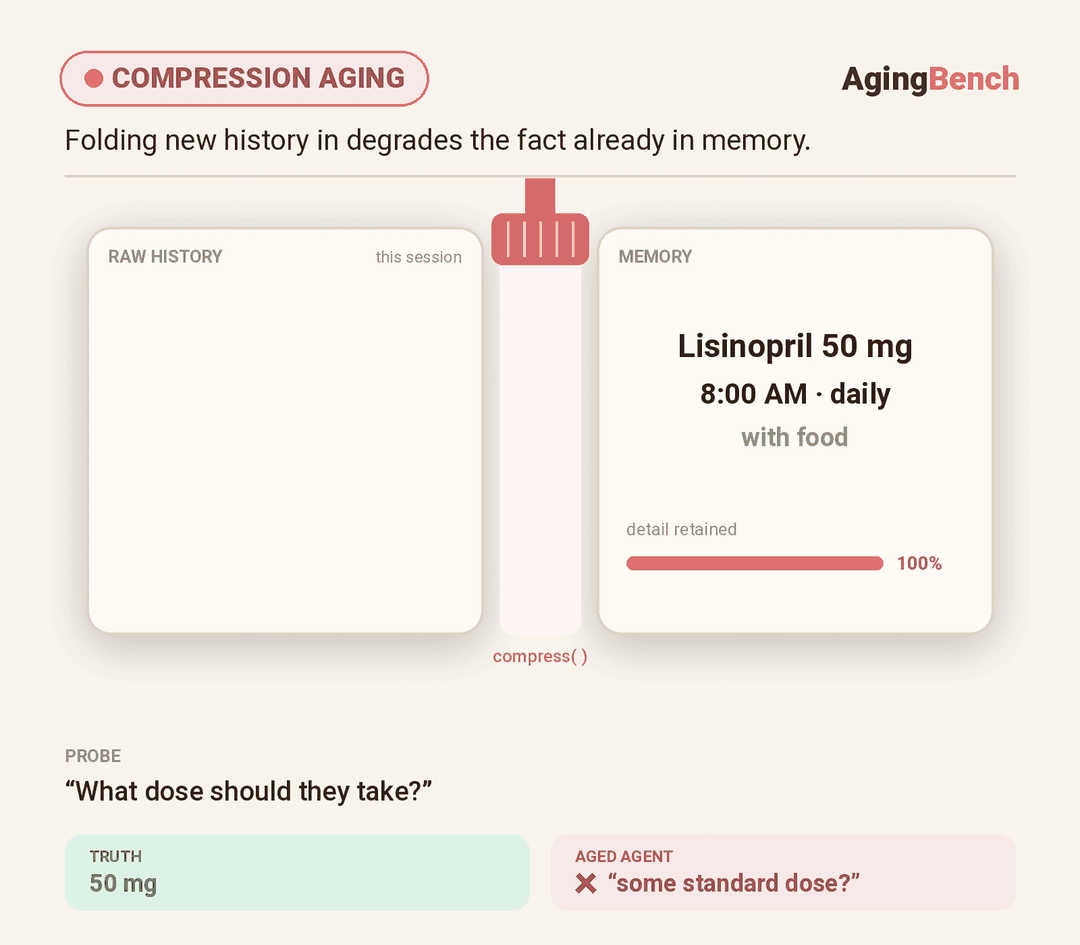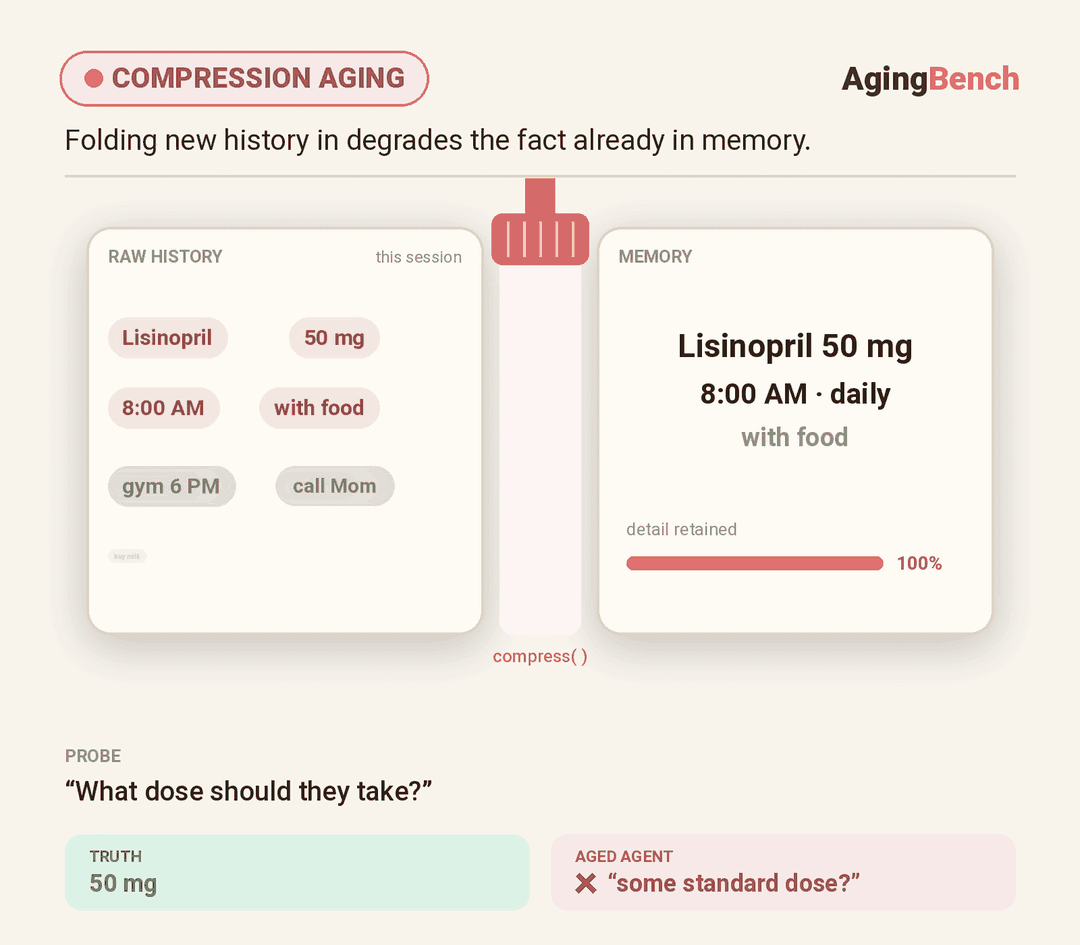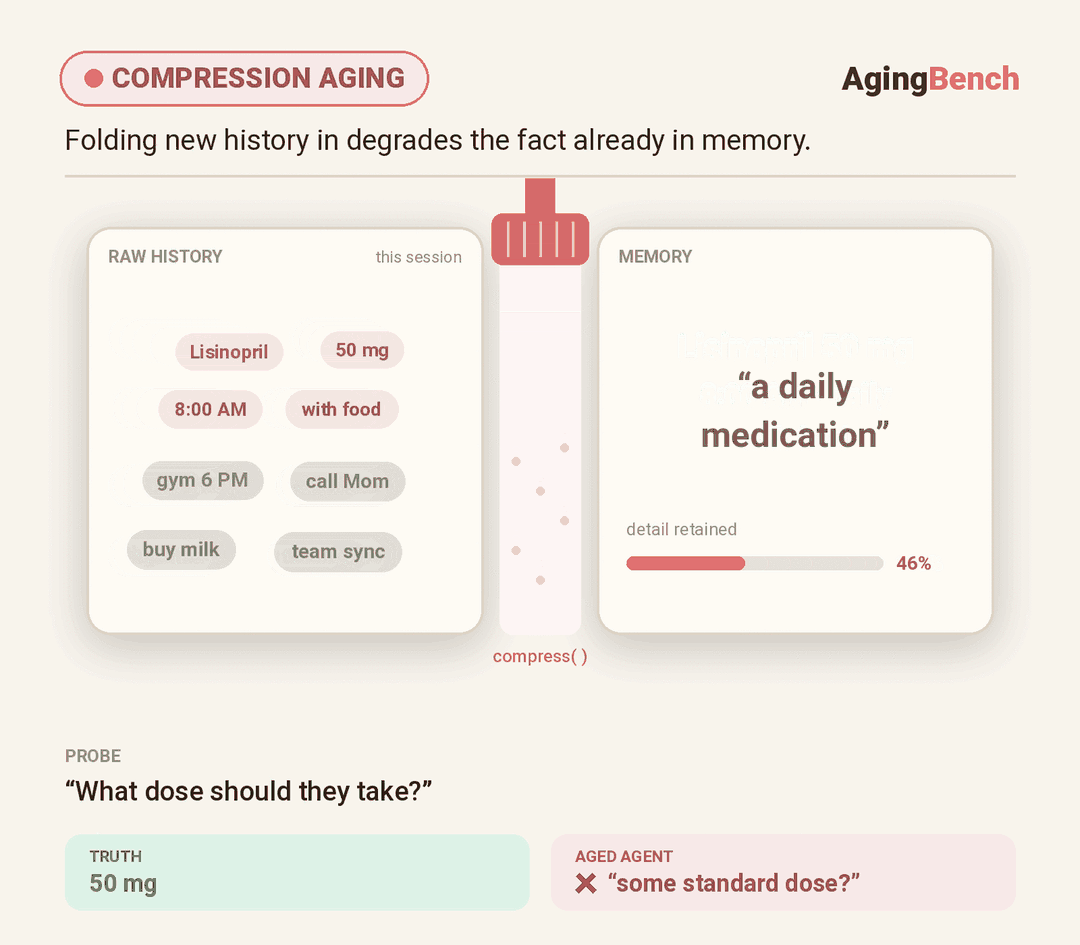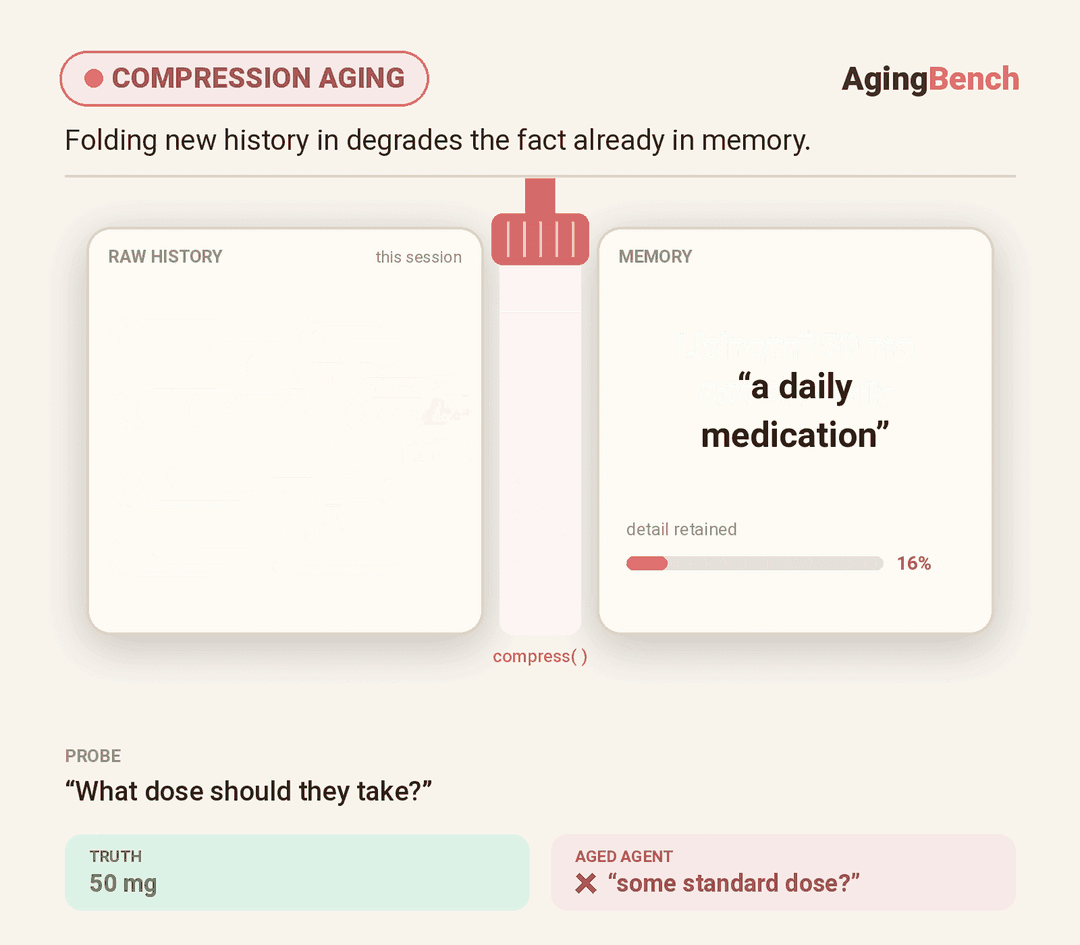
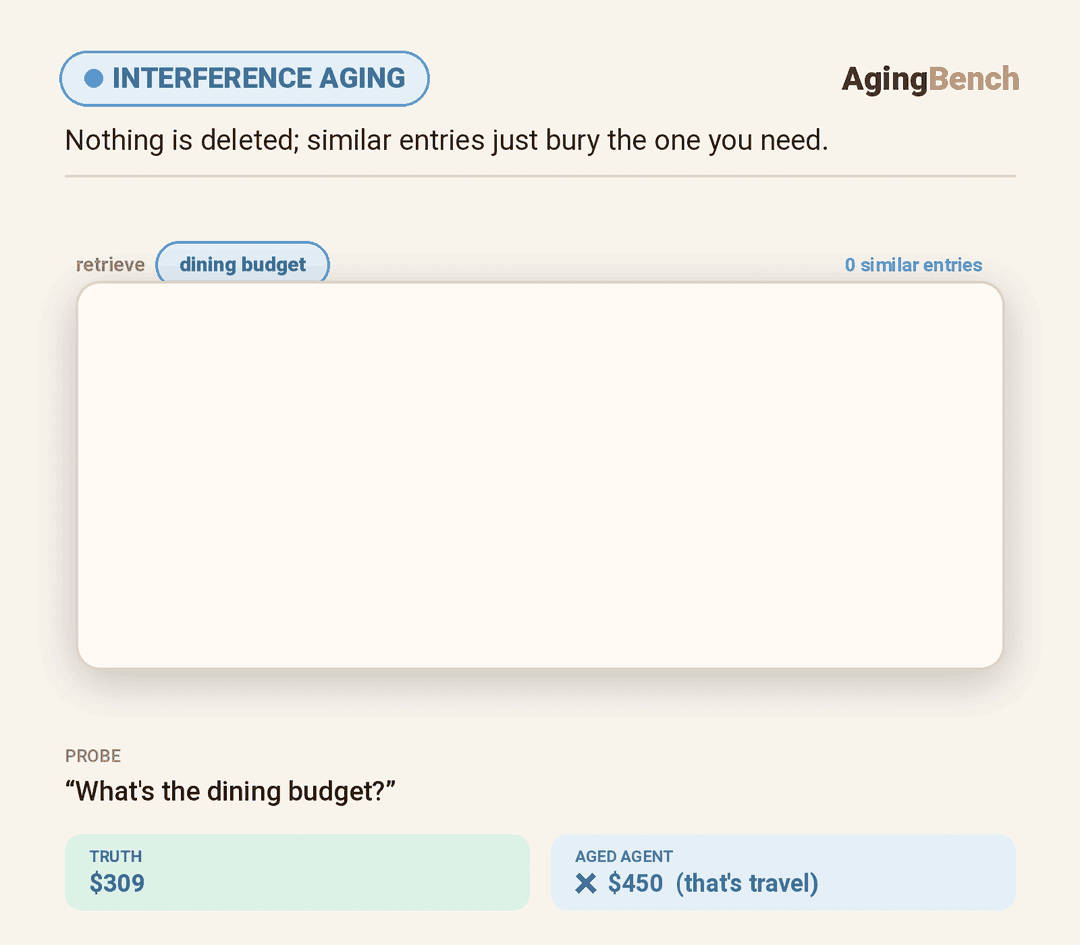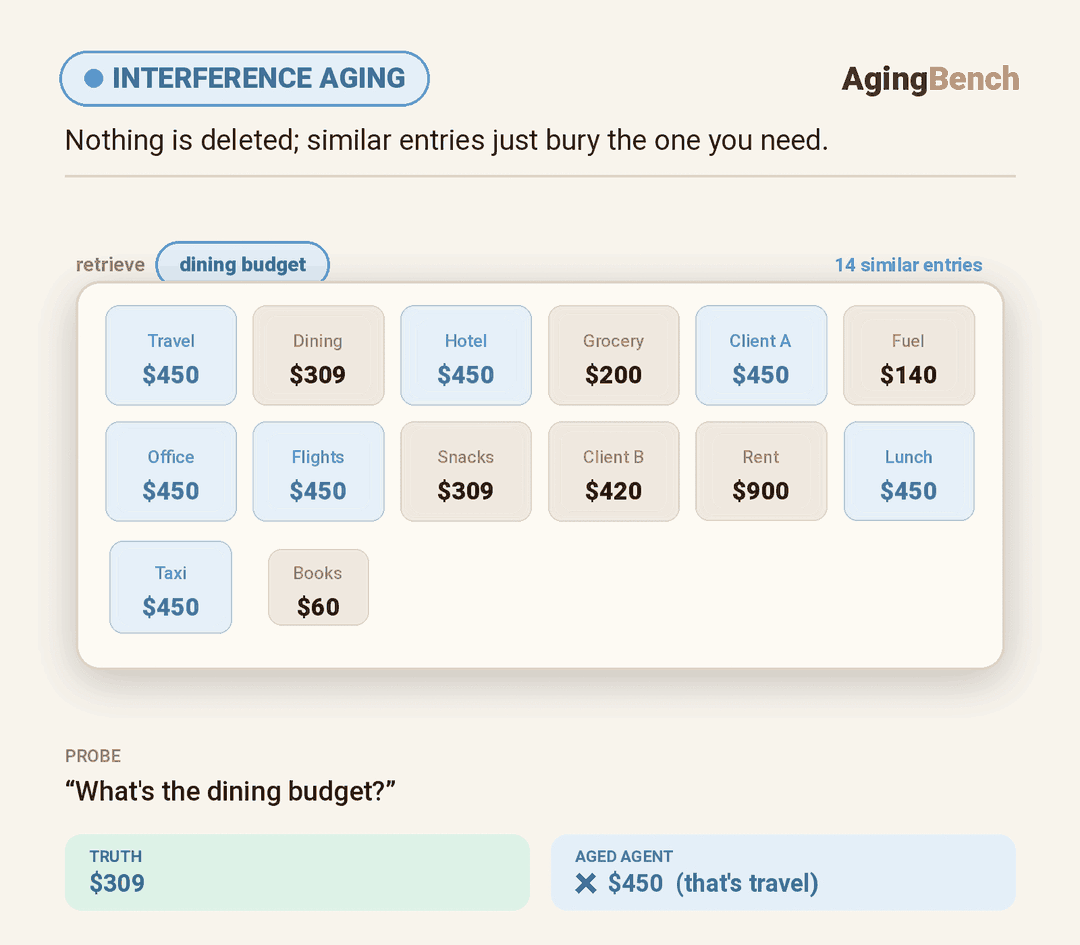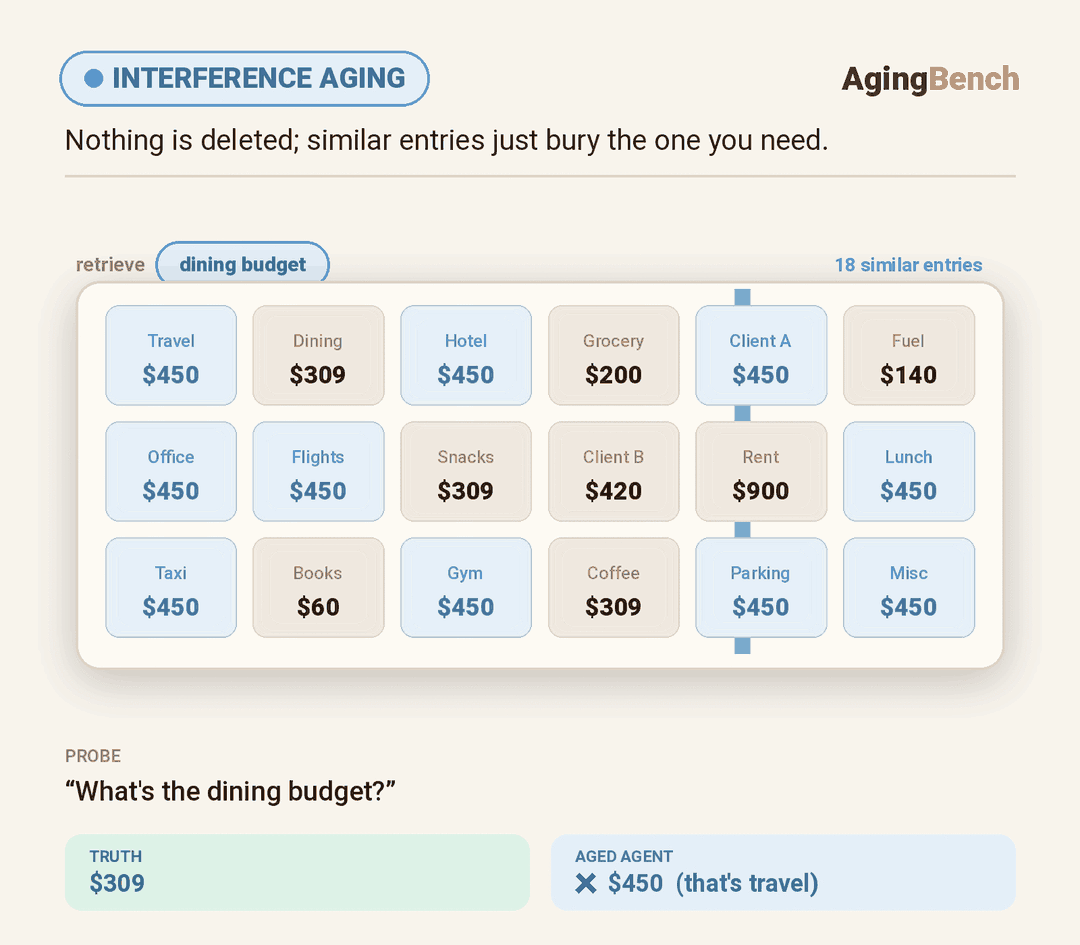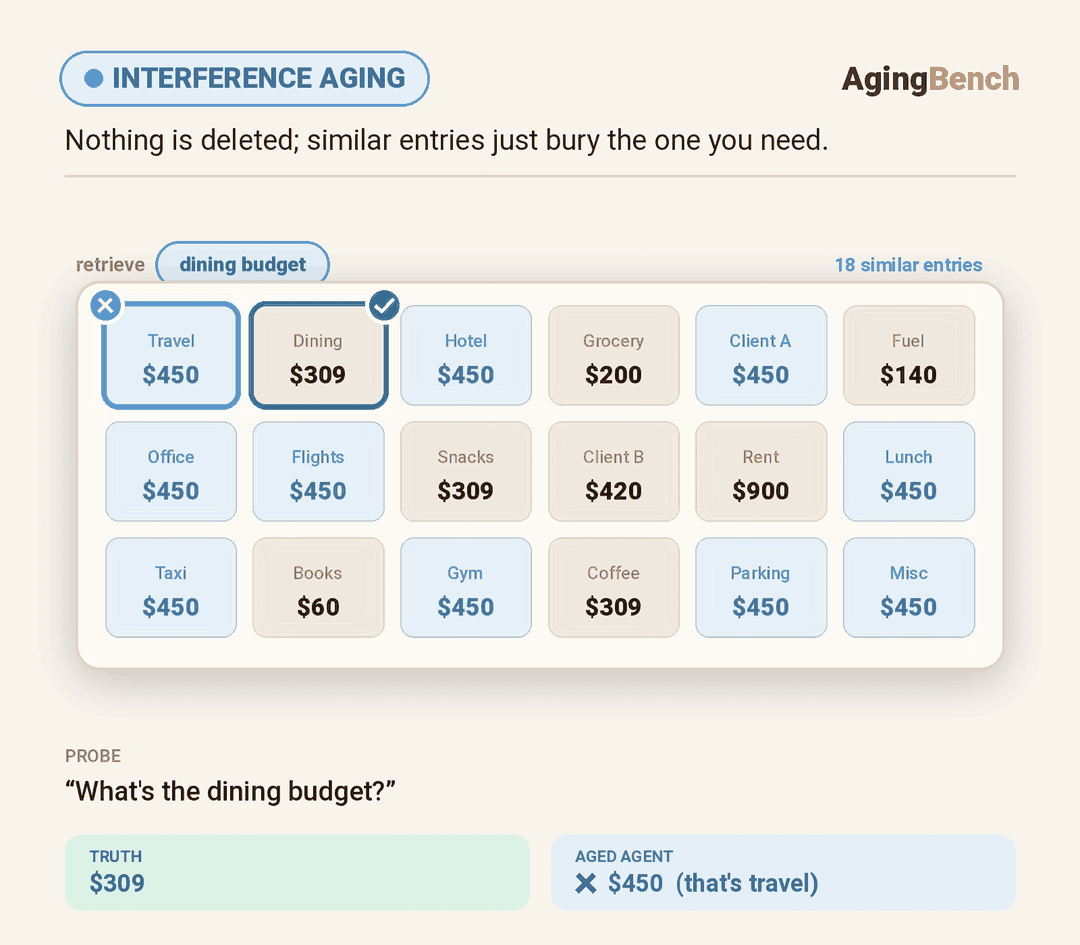
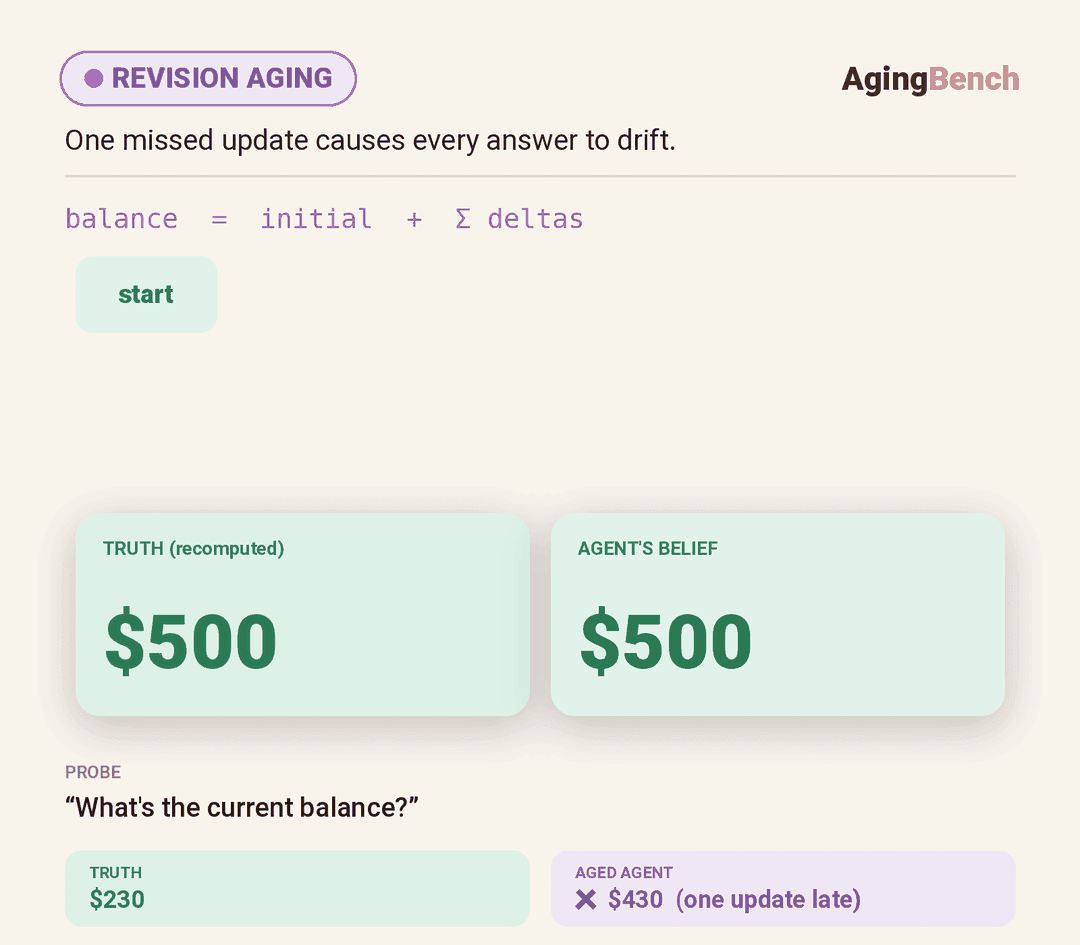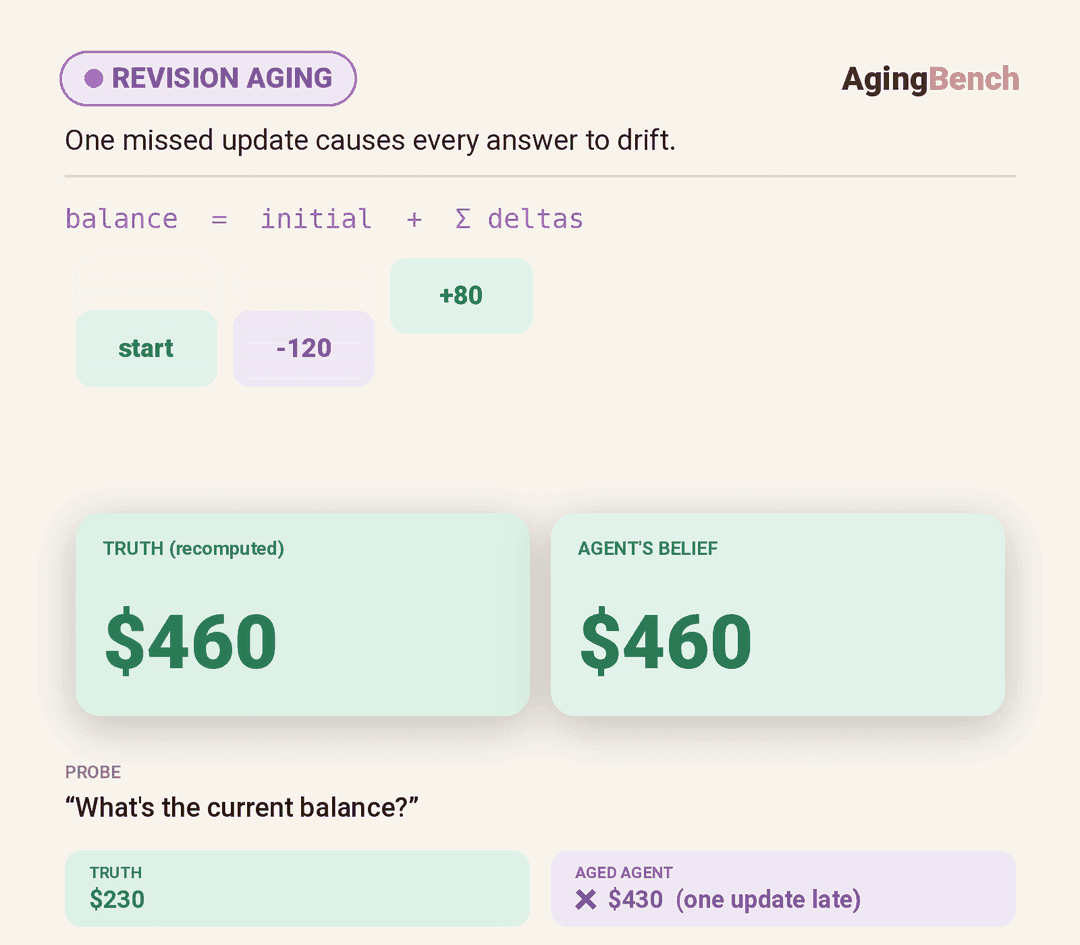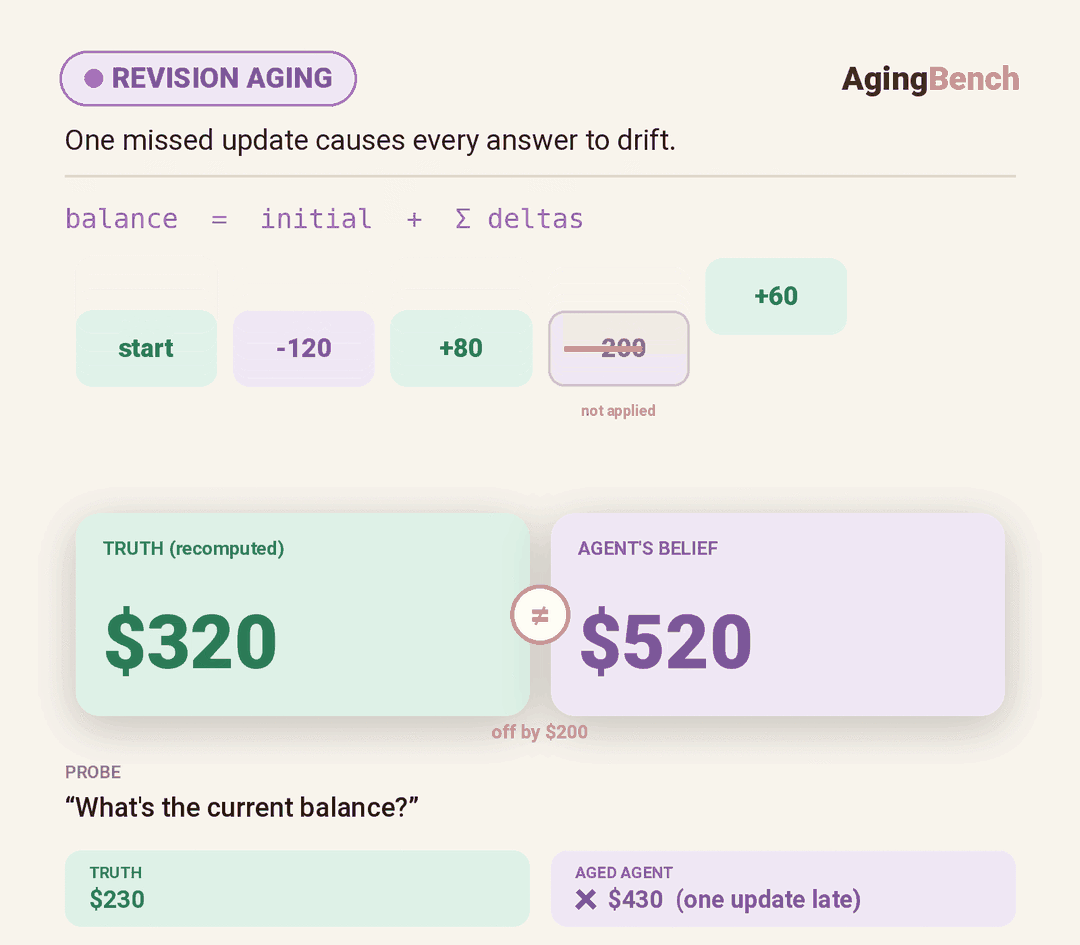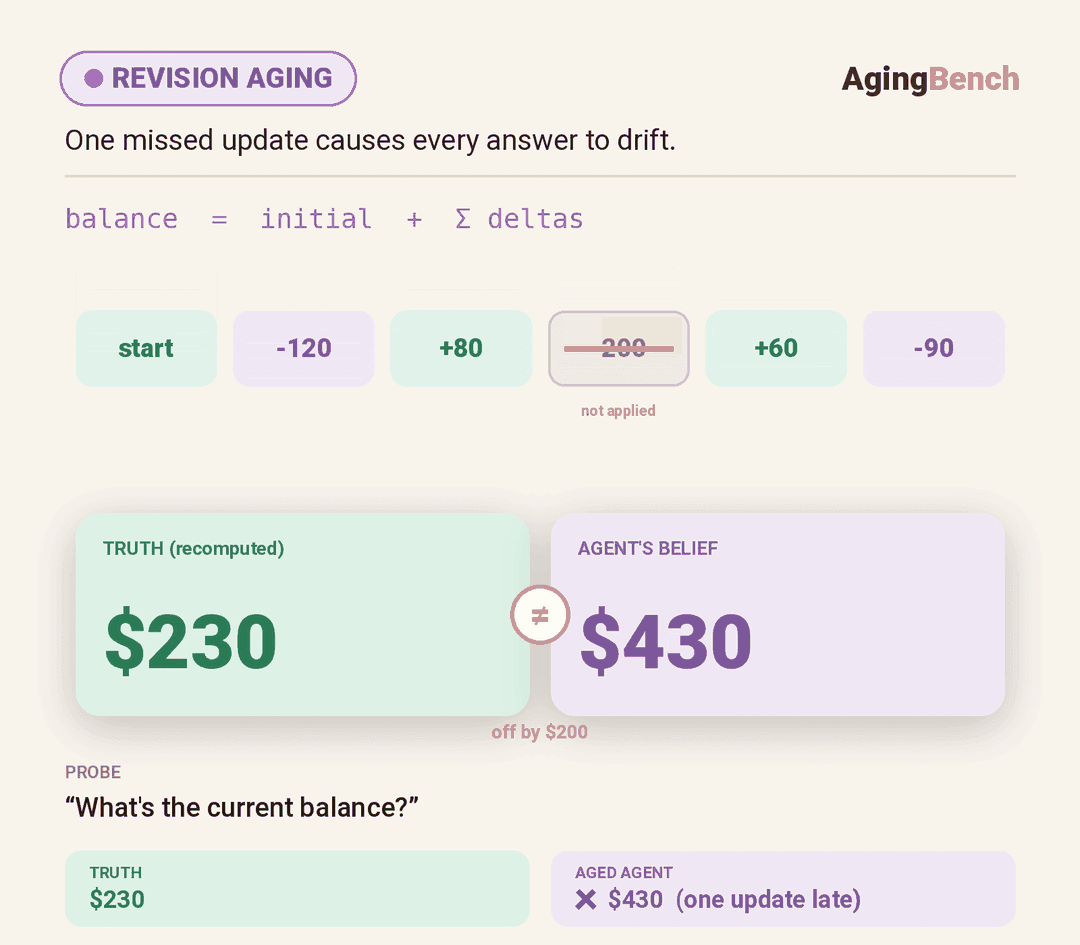
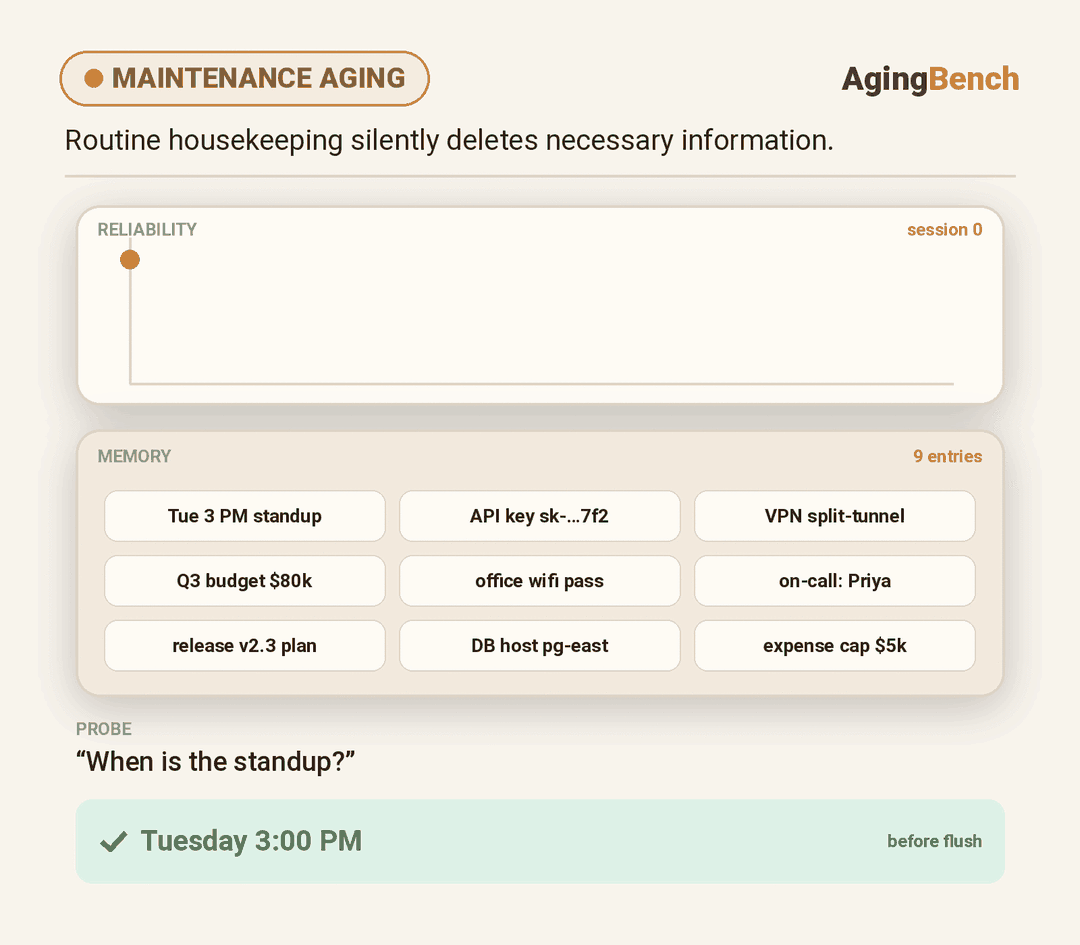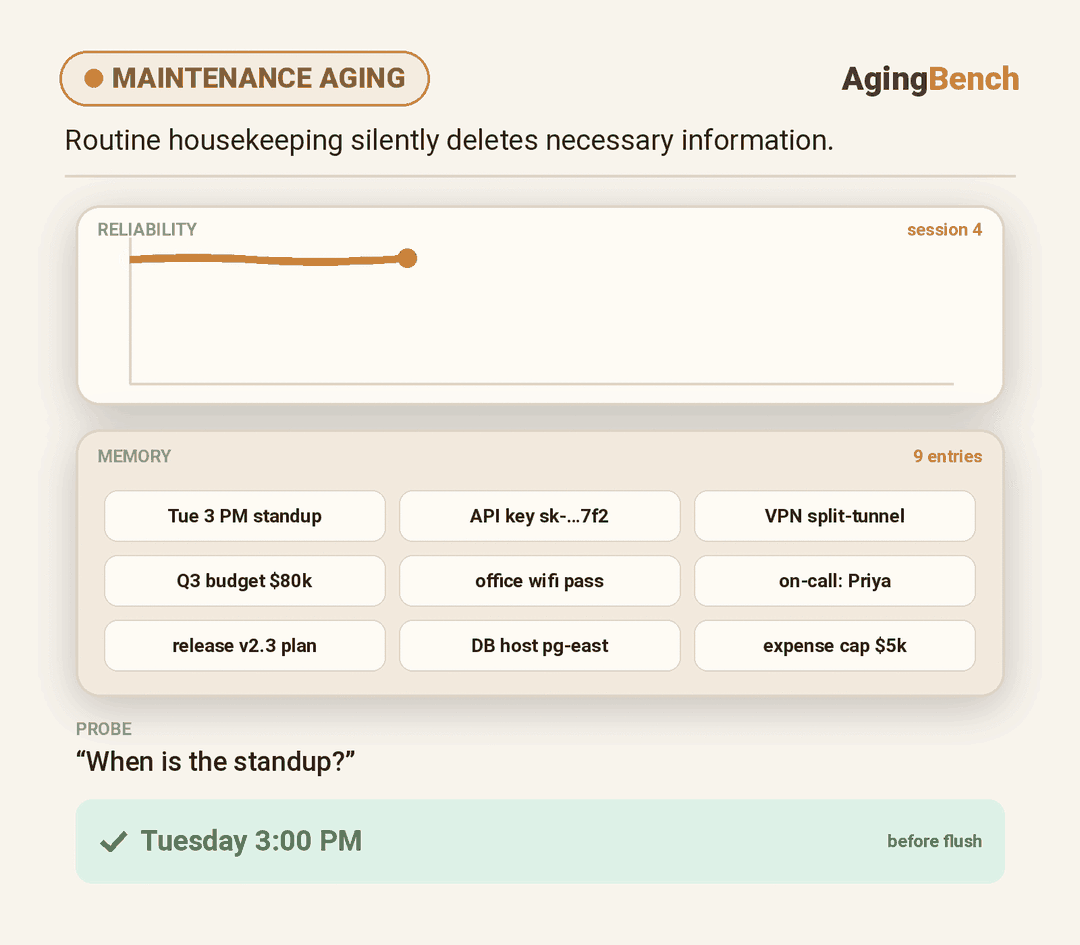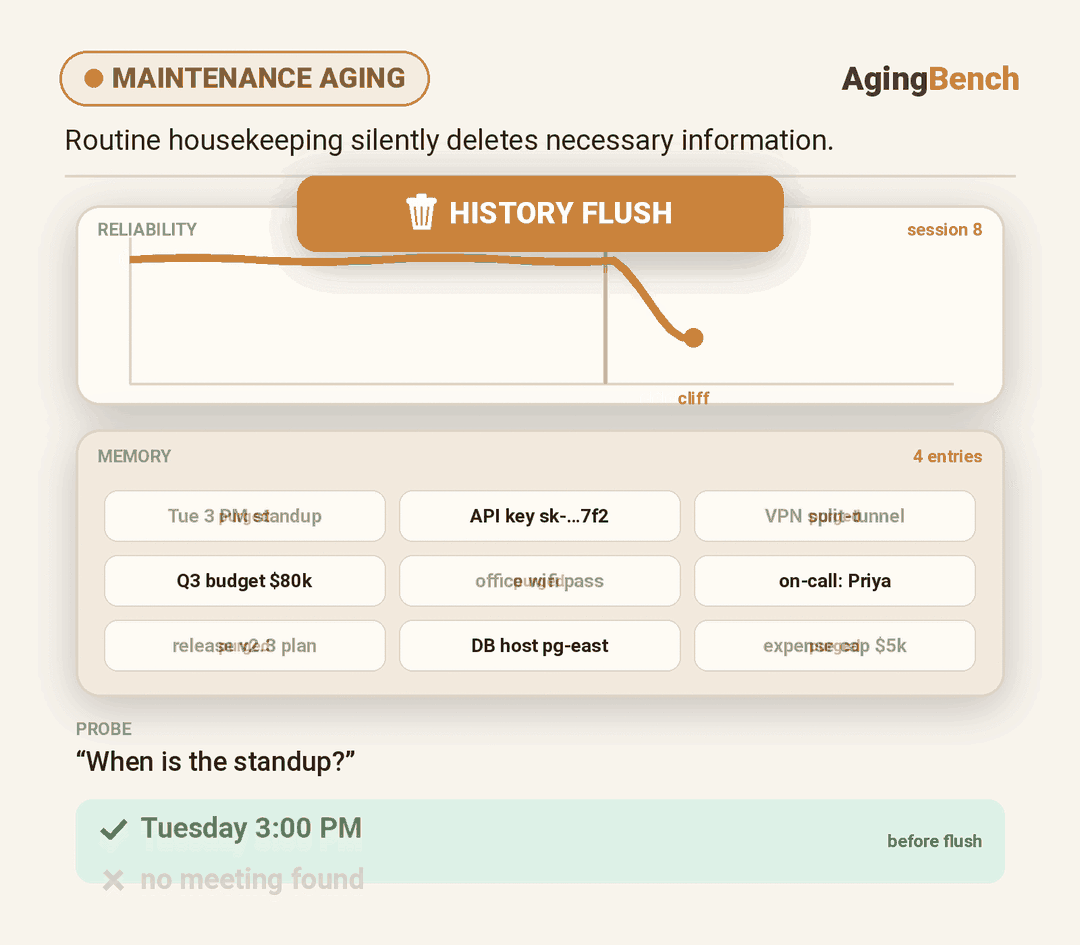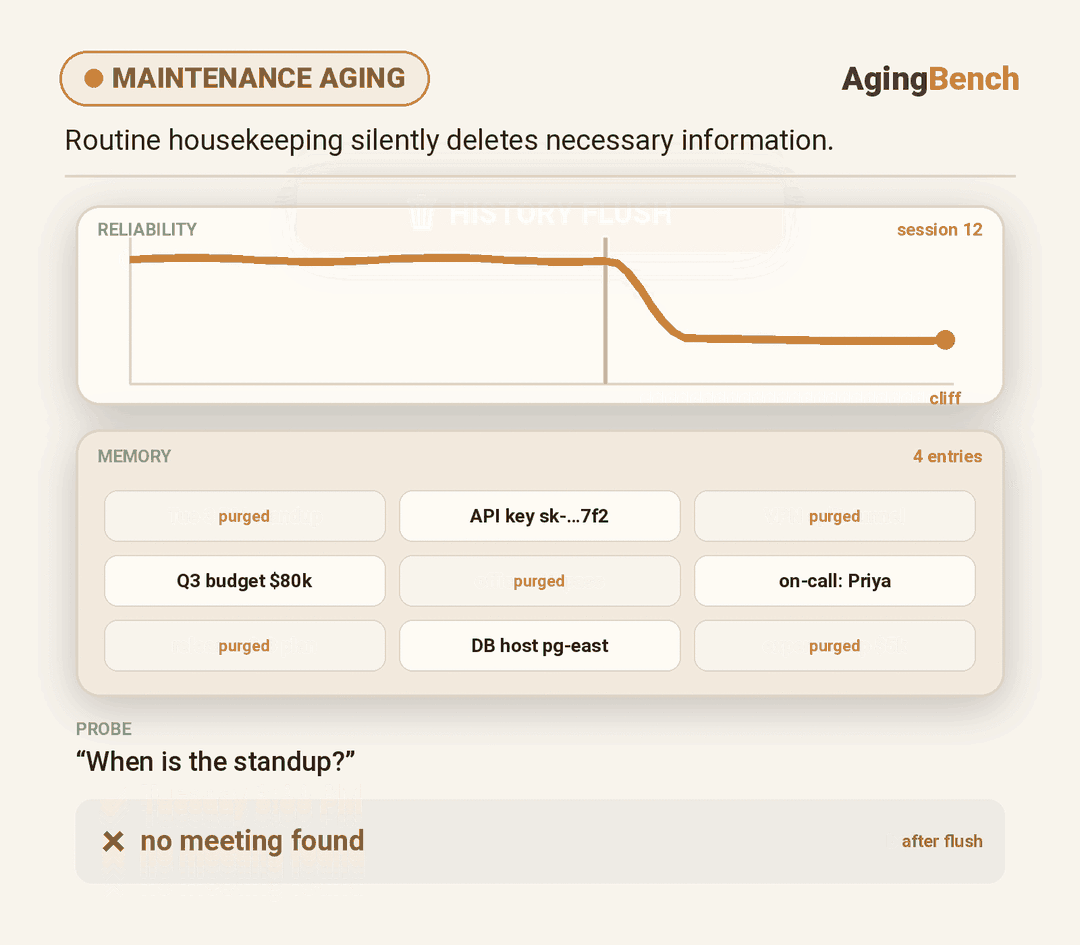
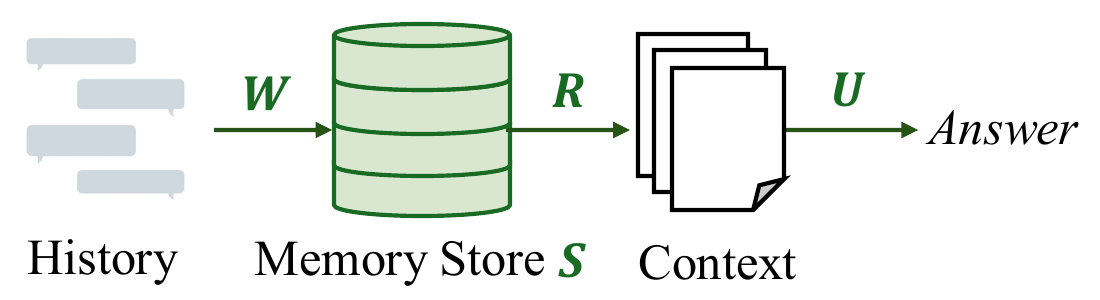
We introduce AgingBench, a longitudinal reliability benchmark for agent lifespan engineering: measuring not only whether deployed agents degrade, but what form the degradation takes and where repair should target. AgingBench organizes agent aging into four mechanisms: compression aging, where write-time summarization drops future-relevant details; interference aging, where accumulated similar memories crowd out the target fact; revision aging, where changed or derived state is not updated correctly; and maintenance aging, where lifecycle events such as flushing or recompaction trigger regressions. To diagnose these failures, AgingBench uses temporal dependency graphs and paired counterfactual probes that produce diagnostic profiles for the write, retrieval, and utilization stages of the memory pipeline.
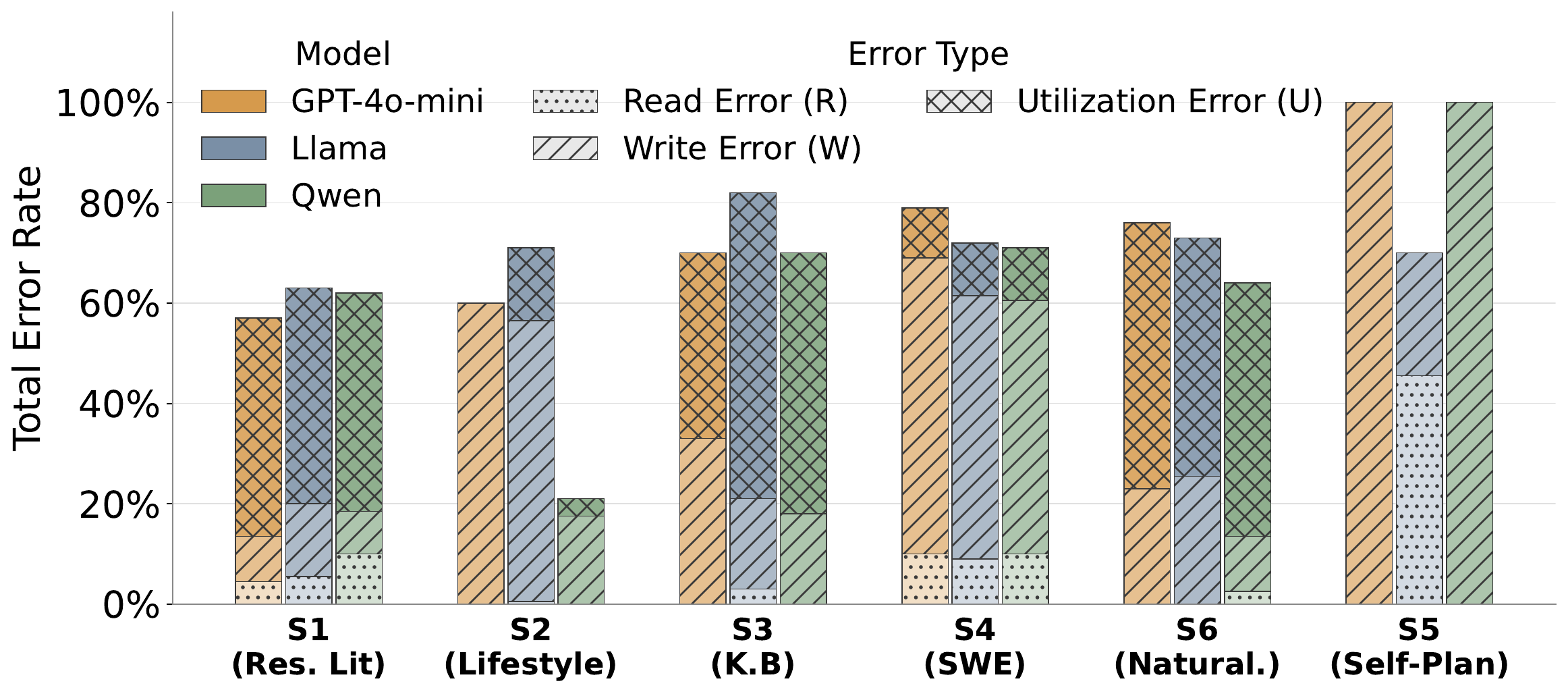
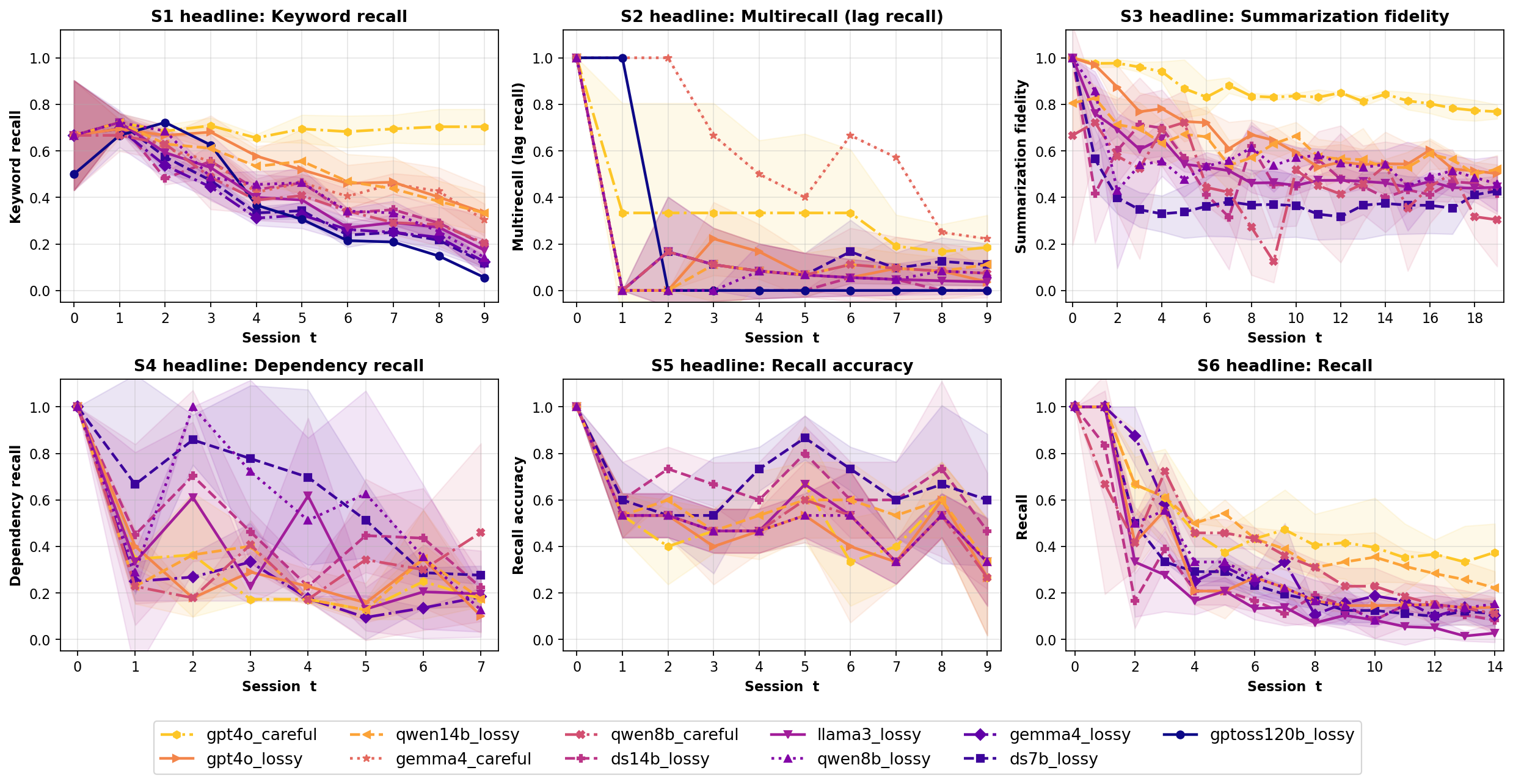
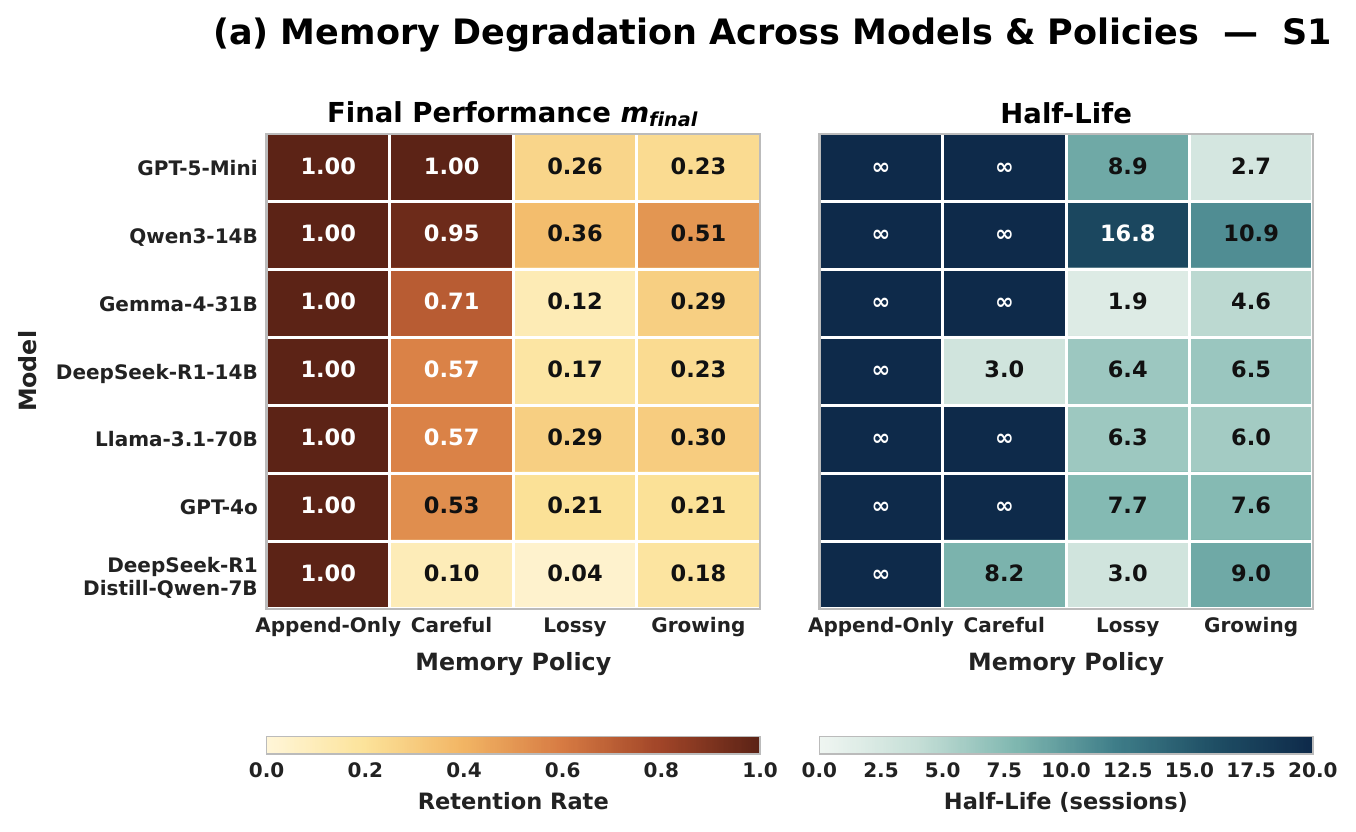
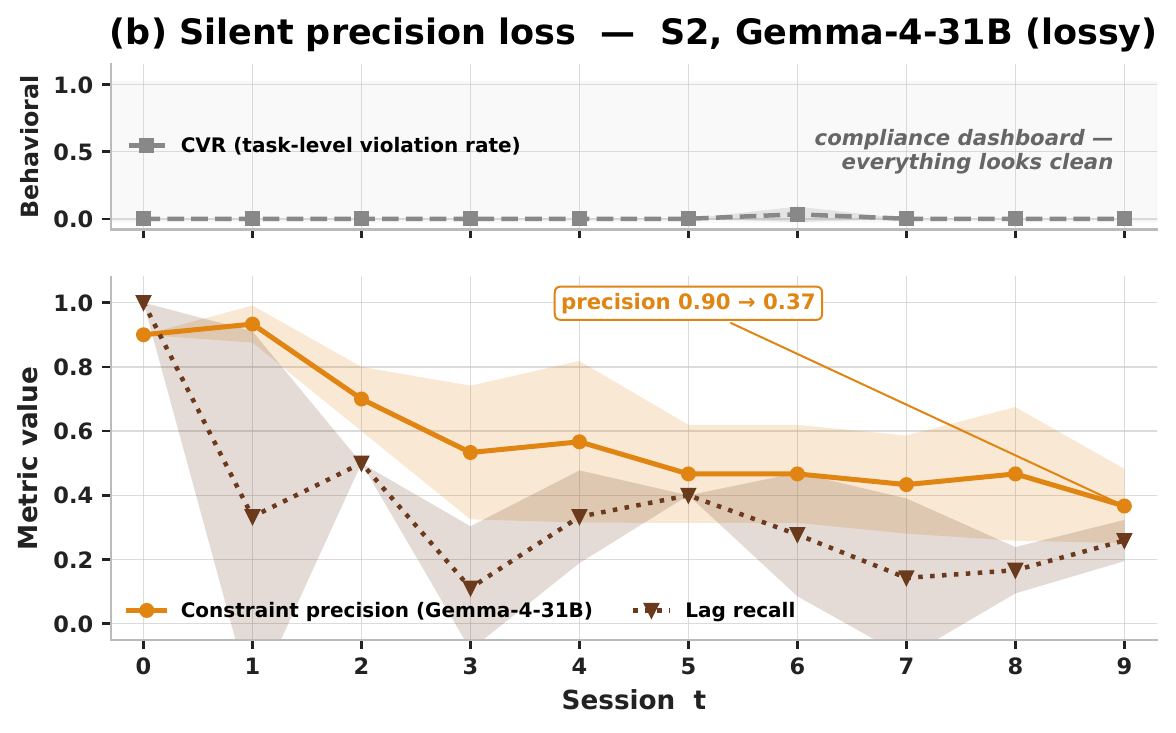
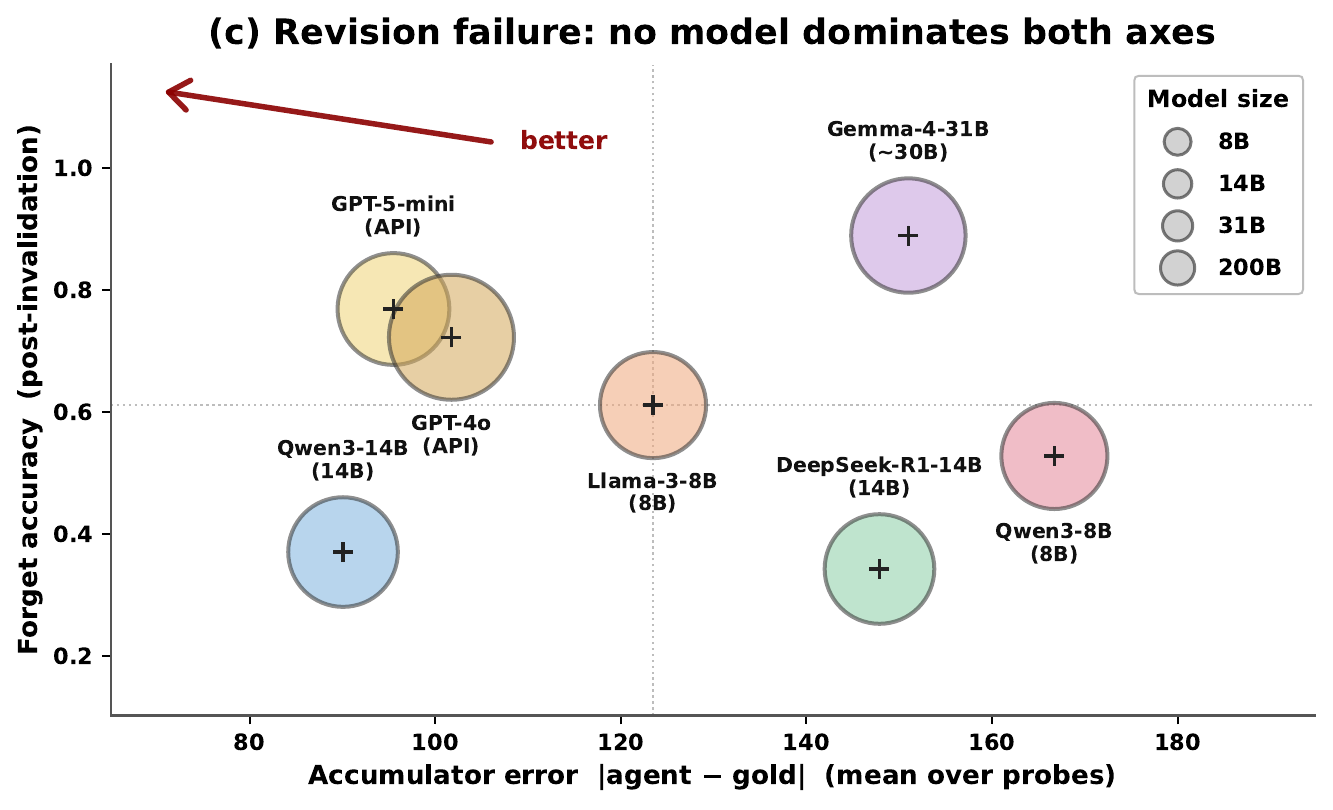
Across 7 scenarios, 14 models, multiple memory policies, and both runner-controlled and autonomous agents, over ~400 runs spanning 8 - 200 sessions show that agent aging is not one-dimensional: behavioral tests can remain clean while factual precision decays; derived-state tracking can collapse sharply within a single model; and the same wrong answer can require different repairs depending on what the diagnostic profile points to. These results suggest that reliable agent deployment requires lifespan evaluation, mechanism-level diagnosis, and stage-targeted repair, not only stronger day-one models.