Telemetry mode reference
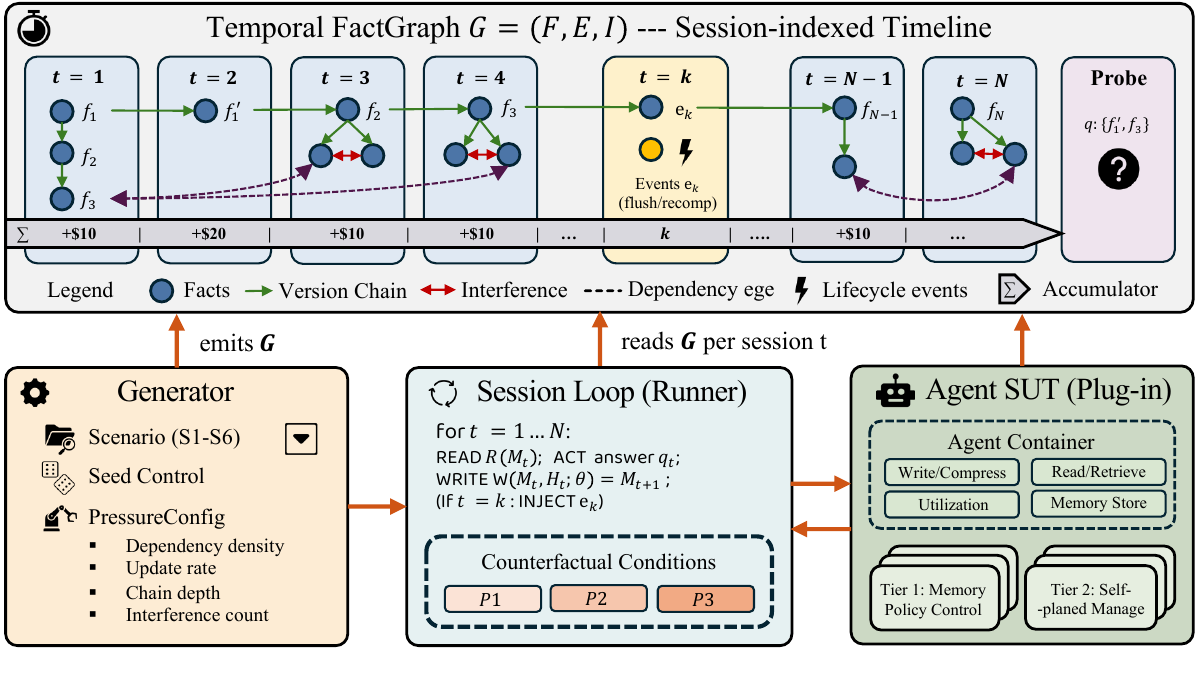
Telemetry mode is the inverse of scenario mode: instead of running constructed probes against your model, it parses a JSONL trace your deployed agent has already produced and infers per-mechanism aging signals from the trace's behavioral DAG — the graph formed by tool calls (names + args), tool results, session boundaries, lifecycle events, and timestamps. This page documents the current telemetry-mode API; recipe cards for each format live on the telemetry page.
Supported trace formats
Seven adapters ship in agingbench/telemetry/adapters/. Each normalizes its native trace shape into a canonical TelemetryRecord stream that downstream inference consumes format-agnostically. Adapters all pass fixture-level parse tests; the extraction recipe (the command to dump a JSONL from a live source) is validated only for the two formats marked ✓ in v0.3.0 — the others depend on third-party SDK versions and are pending live validation.
| format | recipe status | input shape |
|---|
claude_code | ✓ verified | Native Claude Code JSONL session files; type + message.usage + sessionId auto-detected. |
generic | ✓ by-design DIY | Best-effort fallback: any JSONL with session_id, role, content, and token-count fields; adapter aliases camelCase + snake_case variants. |
openai_assistants | ⓘ reference | Mixed thread.message / thread.run / thread.run.step objects from the Assistants API export. |
openhands | ⓘ reference | OpenHands SDK event log: {source, action, observation, llm_metrics} per event. |
langfuse | ⓘ reference | Langfuse SDK exports or REST-API JSON downloads; accepts both camelCase and snake_case field names. |
langsmith | ⓘ reference | Routed through generic; user is responsible for reshaping LangSmith run JSON to the generic field tuple. |
otlp | ⓘ reference | OpenTelemetry JSON spans; recognizes both the new gen_ai.* semconv and the legacy llm.* namespace. |
Recipe-status legend: ✓ verified = recipe tested end-to-end against a real source in v0.3.0; ⓘ reference = adapter parses correctly against fixtures, but the documented extraction command depends on SDK / exporter versions and hasn't been live-validated. If you already have a JSONL of the matching shape, the parser handles it regardless.
Trace preprocessing (Claude Code only)
Claude Code stores each conversation as a separate <uuid>.jsonl under ~/.claude/projects/<encoded-cwd>/. To analyze cross-session aging, those fragments must be concatenated into a single timestamp-sorted JSONL. The bundled helper does it in one command (other adapters already export a single file, so they don't need this step):
python -m agingbench.telemetry.prepare_trace ~/.claude/projects/<your-project-dir>
# → wrote ~/.claude/projects/<your-project-dir>/agingbench_trace.jsonl (N events)
Source: agingbench/telemetry/prepare_trace.py. Python API: from agingbench.telemetry import prepare_trace; out = prepare_trace("~/.claude/projects/<dir>").
Deployment profile
A profile bundles deployment-specific defaults — native outcome-event mappings, subject-linkage keys, per-mechanism weights, session-detection heuristics, and supplementary privacy patterns. Two profiles ship:
generic — no domain assumptions. Outcome events must come from a separately-supplied OutcomeEvent JSONL because the profile cannot extract them natively.code_assistant — tailored for software-engineering agents (Claude Code, Cursor, Aider, Codex CLI, OpenHands). Maps native events (pr_merged, ci_pass, commit_reverted, completion_accepted, …) to OutcomeEvent.outcome; weights revision at 1.5× over the other mechanisms.
Profiles are loaded via load_profile(name). Per-call overrides:
from agingbench.telemetry import trace_to_card_v11
r = trace_to_card_v11(
trace_jsonl="trace.jsonl",
trace_format="claude_code",
profile="code_assistant",
overrides={"mechanism_weights": {"compression": 1.2}}, # deep-merged
)
Profile YAML source lives in agingbench/telemetry/profiles/; full structure (outcome_rules, subject_linkage, mechanism_weights, session_detection, privacy_patterns) documented inline as comments.
OutcomeEvent extractors
Extractors derive OutcomeEvents from trace records when the trace doesn't carry them natively. Pass a list of extractor names via extract_outcomes=[...] on trace_to_card_v11. v0.3.0 ships three:
claude_session_flags — derives success/fail signals from Claude Code's session-completion markers (slash-command exits, tool-call abort flags).git_log — walks git history alongside the trace's timestamps; commits that immediately follow an agent reply count as success, reverts count as revision_fail.record_patterns — generic regex-based pattern matching over record text (configurable via the profile YAML's outcome_rules).
Note: outcome events are optional. Most production traces (Claude Code, OpenHands, etc.) don't carry them; telemetry mode uses the cross-session consistency probe below as the outcome-free headline source. Specs in agingbench/telemetry/outcome_extractors.py. Custom extractors register via register_extractor(name, fn).
Per-mechanism inference (behavioral DAG)
Each of the four aging mechanisms gets a dedicated inference module under agingbench/telemetry/inference/. The primary signals are structural — derived from the trace's behavioral DAG rather than from text patterns over prompt/response strings:
| mechanism | primary signals (structural) | file |
|---|
compression | saturation rate (input_tokens / ctx_window), context-noise ratio trajectory, tool-argument specificity slope (P3) | compression.py |
interference | tool-name KL divergence vs early-session baseline, embedding-based goal-anchor drift (P2), tool-result lineage continuity (P4) | interference.py |
revision | tool-result update propagation (P1) with a three-tier fallback — see next subsection | revision.py |
maintenance | lifecycle shock detection (model swap, ctx drop, cache spike, system change, /clear command) + cumulative shock_damage_trajectory: damage magnitude per shock uses a 3-tier preference — outcome_rate_delta (when outcomes linked) → avg_response_tokens_delta/100 (universal) → latency_p50_delta_ms/1000 (when duration_ms present) | maintenance.py |
Cross-session consistency probe (P5)
The load-bearing telemetry-mode signal: consistency.py clusters user turns by sentence-transformer cosine similarity (Jaccard fallback when the encoder isn't available), then for each repeat-task cluster compares first-vs-last occurrence on tool-path Jaccard and response cosine. Output keys on the consistency block:
behavior_drift_at_repeat — aggregate drift in [0, 1]; used as the headline metric when no OutcomeEvents are presentconsistency_drop_trajectory — per-session cumulative drift (flat list; same shape as the per-mechanism trajectories)tool_path_jaccard_drop_mean, response_cosine_drop_mean — component scoresn_repeated_tasks_detected, cluster_sizes — coverage diagnostics
Three-tier revision fallback
Revision (the "agent reverted to a stale value" signal) gets the most adapter-sensitive treatment. infer_revision() dispatches to one of three tiers depending on what the trace carries:
- P1 · tool_result_update_propagation (preferred) — requires
tool_calls[].result_summary. Tracks (entity, attribute) → [(t, value)] across the trace; counts agent args that reference a value older than the most-recent result for the same key.
- tool_argument_self_reversion (middle) — requires only
tool_calls[].args (universal across adapters). Counts v1 → v2 → v1 patterns on agent arg values; identifier-shaped values (UUIDs, file paths, ISO timestamps, long hex hashes) are excluded so re-references aren't mistaken for revisions.
- user_correction_text_patterns_fallback (final) — English regex over user prompts. Blocks tagged with this
derived_from label are visually downweighted on the card.
Both Tier 1 and Tier 2 emit canonical value_supersession_* field names AND legacy per_session_violation_* / violation_trajectory_* aliases so existing visualisations (including the website sparkline) keep rendering without changes.
Dominant-mechanism selector
Implementation: agingbench/telemetry/inference/_selector.py. The selector decides which single mechanism (if any) leads the Lifespan Card. Logic:
- Classify each fired signal as independent or shared. Independent signals diagnose a single mechanism (saturation → compression; tool-KL drift → interference; value supersession → revision; lifecycle event → maintenance). The shared signal — lineage continuity drop — is compatible with multiple mechanisms and is not enough on its own.
- Gate. A mechanism is eligible only if at least one of its independent signals fires. Shared signals add weight on top but cannot stand alone.
- Argmax. Among gated mechanisms, the highest credited severity score wins unconditionally. Ties break by mechanism order (compression, interference, revision, maintenance).
- Empty case. If no mechanism passes the gate, the card reports
reason: no_independent_evidence with the list of compatible mechanisms — signature and repair lines stay blank.
Lifespan Card surface (signature + repair)
When the selector returns a single dominant mechanism, two static lookups in agingbench/telemetry/card_lookups.py produce the card's human-readable closing lines:
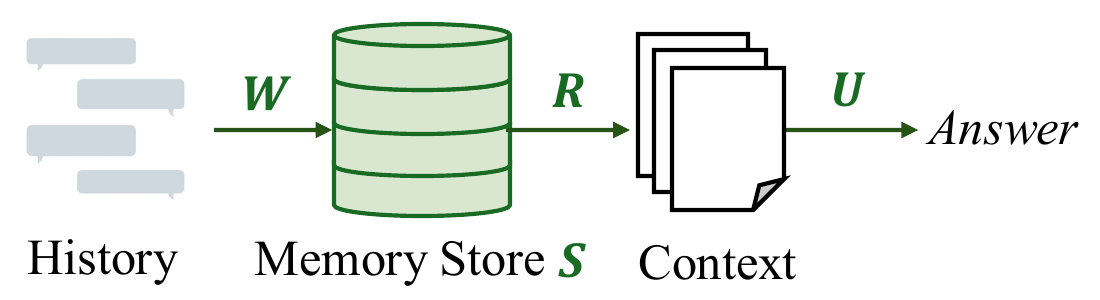
MECHANISM_TO_STAGE — maps mechanism → memory-pipeline stage (W = write, R = retrieval, U = utilization, S = store). diagnostic_signature("revision") returns "utilization-dominant (U-stage)".MECHANISM_TO_REPAIR — maps mechanism → recommended repair recipe. recommended_repair("revision") returns "typed state for derived values...".
A pure-Python card renderer (card_render.render_card_ascii(trace_audit)) produces the rich-format ASCII card shown in the demo and used by the website's 📸 Save as PNG action.
Headline policy (outcome-free by default)
The card's top-line "how fast is this aging" metric is selected dynamically based on what the trace carries — tiers tried in order:
half_life — when OutcomeEvents are present (or an extractor fires)behavior_drift_at_repeat — when ≥ 1 repeat-task cluster is detected (each cluster ≥ 2 occurrences)aging_trend — when the aggregate per-session severity sum across the four mechanism blocks is monotonically rising over ≥ 3 sessions (the aggregate now includes the per-session diff of shock_damage_trajectory)maintenance_shock_damage — when the maintenance block's cumulative shock-damage signal is rising and ≥ 3 shocks fired. Catches front-loaded shock patterns whose per-session-delta trend doesn't qualify for tier 3not_measurable — when none of the above apply
The headline.source field carries the chosen tier. headline.aging_detected is true when the chosen signal exceeds a meaningful threshold (decay slope < −0.01, m0→m_final drop ≥ 10%, behavior drift > 10%, aging trend slope > 0.01, OR shock_damage_verdict == rising_degradation with n_shocks ≥ 3). The shock-damage clause fires regardless of which tier produced the headline label, so a trace whose dominant aging is maintenance-driven flags aging_detected: true even when the headline label is — for example — a behavior-drift number from tier 2.
Coverage + trajectory verdicts
Every per-mechanism inference block carries two verdict strings so a low score can never be confused with "agent didn't age." The full enum:
Coverage (coverage.verdict) — how much signal the trace gave us for this mechanism:
strong — many sessions with fired tests; conclusion is well-supportedadequate — enough sessions for a defensible readweak — borderline; treat the score as suggestive onlyunderpowered — too few sessions or too few fired testsno_test_fired — the inference test conditions never triggered (e.g. revision needs a value to change at least once)
Trajectory (<metric>_verdict) — the shape of the per-session series, made saturation-aware so floored/ceilinged metrics aren't mis-read as flat:
no_signal, flat — no measurable changerising_degradation / rising_healthy — series is climbing; one direction means aging, the other means improvement, depending on the metricfalling_degradation / falling_healthy — series is droppingfloor_degradation / floor_healthy — series has bottomed out at zero (or near-zero)ceiling_degradation / ceiling_healthy — series has saturated at the ceiling
Conceptual mapping to scenarios mode
The four-mechanism vocabulary is inherited from scenarios mode, where each mechanism is operationalised against the gold dependency DAG. Without gold, telemetry signals are proxies — but not all equally faithful:
- Revision and Maintenance map cleanly: P1's tool-result-update propagation is operationally analogous to scenarios-mode revision probes; lifecycle-shock pre/post deltas mirror the maintenance probe structure.
- Compression and Interference map indirectly: telemetry signals (saturation, KL drift, lineage drop) are necessary conditions and downstream symptoms, not direct measurements of the mechanism without a gold fact list / confusable cluster definition.
Net framing: telemetry mode performs mechanism-level triangulation (multiple structural signals stacked to constrain the mechanism story), where scenarios mode performs mechanism-level identification against gold. Both useful; not interchangeable.
For the math
Per-mechanism inference functions live in agingbench/telemetry/inference/ — one file per mechanism (compression.py, interference.py, revision.py, maintenance.py), plus the cross-session consistency probe (consistency.py), the dominant-mechanism arbitration (_selector.py), shared verdict thresholds (_verdict.py), and lightweight text/clustering helpers (_text_utils.py). Lifespan-card-rendering helpers live alongside in card_lookups.py + card_render.py; the Claude Code preprocessor is in prepare_trace.py. End-to-end pipeline + design notes in agingbench/telemetry/README.md.